Mozilla.ai explica estandarización del razonamiento en LLMs | Keryc
Mozilla.ai publicó una entrada que mira de cerca cómo estandarizar el «contenido de razonamiento» de los modelos GPT y hacerlo interoperable entre distintos proveedores. ¿Por qué debería importarte si usas modelos para productos, investigación o simplemente curioseas sobre IA? Porque ahora la forma en que los modelos cuentan cómo piensan puede variar según quién los hospeda. (blog.mozilla.ai)
Qué está pasando
OpenAI lanzó gpt-oss, un modelo de razonamiento con pesos abiertos que permite ver la salida intermedia, es decir, el contenido de razonamiento o "chain of thought". Mozilla.ai analizó cómo ese tipo de salida no encaja perfectamente en la especificación tradicional de la API de Completions, lo que obliga a cada proveedor a añadir extensiones o adaptar la interfaz. Esto fue publicado por Mozilla.ai el 12 de agosto de 2025. ()
Los "modelos de razonamiento" generan pasos intermedios además de la respuesta final. El problema real es que la especificación de API ampliamente adoptada no contempla ese bloque de salida extra.
Por qué importa esto hoy
Imagina que trabajas en una app que compara respuestas entre modelos para elegir el mejor proveedor. Si cada servicio devuelve el razonamiento con una clave distinta, tu trabajo se complica: más transformaciones, más riesgo de errores, menos transparencia.
Mozilla.ai plantea que la interoperabilidad es crítica: sin un estándar, perderás comparabilidad y trazabilidad cuando quieras evaluar cómo llegó un modelo a una respuesta, no solo qué respondió. (blog.mozilla.ai)
La propuesta práctica: any-llm
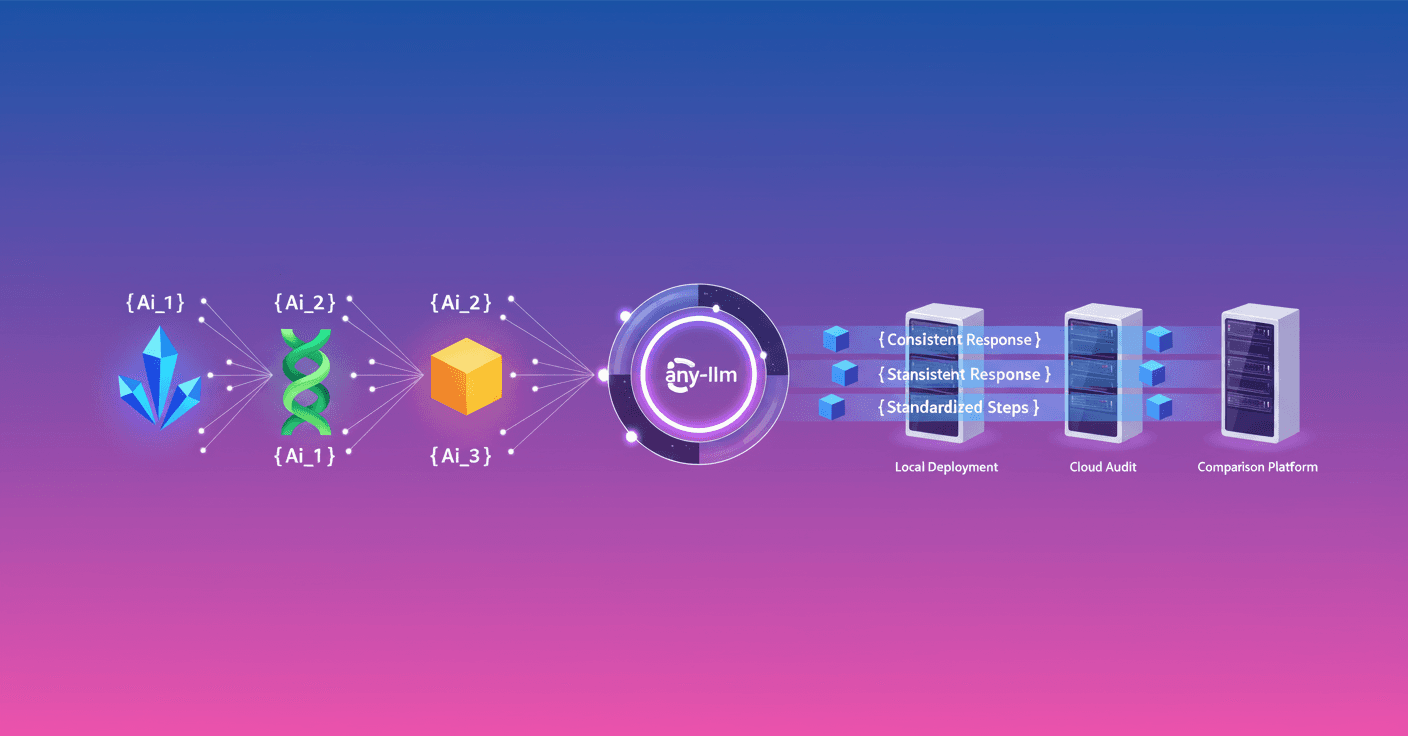
La respuesta técnica que revisa Mozilla.ai es any-llm, una librería que unifica cómo se accede a diferentes proveedores y estandariza la forma en que se captura el contenido de razonamiento. Con any-llm puedes recibir respuestas consistentes (y tipadas con Pydantic) desde proveedores locales y remotos sin reescribir tu lógica de extracción. (blog.mozilla.ai)
Un ejemplo concreto
Mozilla.ai mostró un ejemplo donde ejecuta el mismo prompt contra modelos hospedados en Groq, Ollama y LM Studio para comparar respuesta y razonamiento. El código ejemplifica cómo any-llm normaliza la salida, de modo que response.choices[0].message.reasoning existe de forma consistente, independientemente del proveedor. Esto facilita probar modelos locales quantizados y modelos remotos sin cambios mayores en tu código. (blog.mozilla.ai)
from any_llm import completion
models = ["groq/openai/gpt-oss-20b", "ollama/gpt-oss:20b", "lmstudio/openai/gpt-oss-20b"]
prompt = "What's a good weekend vacation option in Europe that costs less than $1000 for two people?"
for model in models:
response = completion(model=model, messages=[{"role": "user", "content": prompt}])
print(response.choices[0].message.content)
print(response.choices[0].message.reasoning)
Consecuencias prácticas para desarrolladores y equipos
Menos fricción para comparar proveedores: cambias de endpoint, no de arquitectura.
Auditoría y explicabilidad: si recoges razonamientos estandarizados, puedes auditar decisiones automatizadas con más rigor.
Menor costo de integración: evitar mapeos ad hoc reduce errores y mantenimiento.
Si has probado modelos locales quantizados en Ollama o LM Studio y luego quieres llevar la misma lógica a un proveedor en la nube, any-llm apunta a hacer ese salto más simple. (blog.mozilla.ai)
Límites y preguntas abiertas
Estandarizar no lo soluciona todo. Todavía quedan preguntas sobre privacidad de razonamientos, trazabilidad de cambios entre versiones de modelos y cómo representar razonamientos largos o multinivel sin perder claridad. Además, que un modelo sea "open-weight" no implica que todo su uso sea transparente ni gratuito; hay matices legales y técnicos que considerar. (blog.mozilla.ai)
Piensa en esto como en adoptar un conector estándar para encender tu equipo. Antes era solo el "enchufe" para obtener respuesta. Ahora queremos que ese enchufe también nos entregue la receta paso a paso de cómo se cocinó la respuesta. ¿Te interesa probarlo en tu próximo proyecto?
¡Mantente al día!
Recibe noticias de IA, lanzamientos de herramientas y productos innovadores directo en tu correo. Todo claro y útil.
Mozilla.ai explica estandarización del razonamiento en LLMs