Mozilla presenta 3W para ejecutar IA en el navegador | Keryc
¿Te imaginas correr un modelo de lenguaje completo dentro de tu navegador, sin llamadas a APIs externas y sin que tus datos salgan de tu equipo? Mozilla.ai publicó un artículo invitado que propone exactamente eso: un enfoque llamado 3W que junta WebLLM, WASM y WebWorkers para ejecutar inferencia y lógica de agentes directamente en el navegador. (blog.mozilla.ai)
Qué es 3W y por qué importa
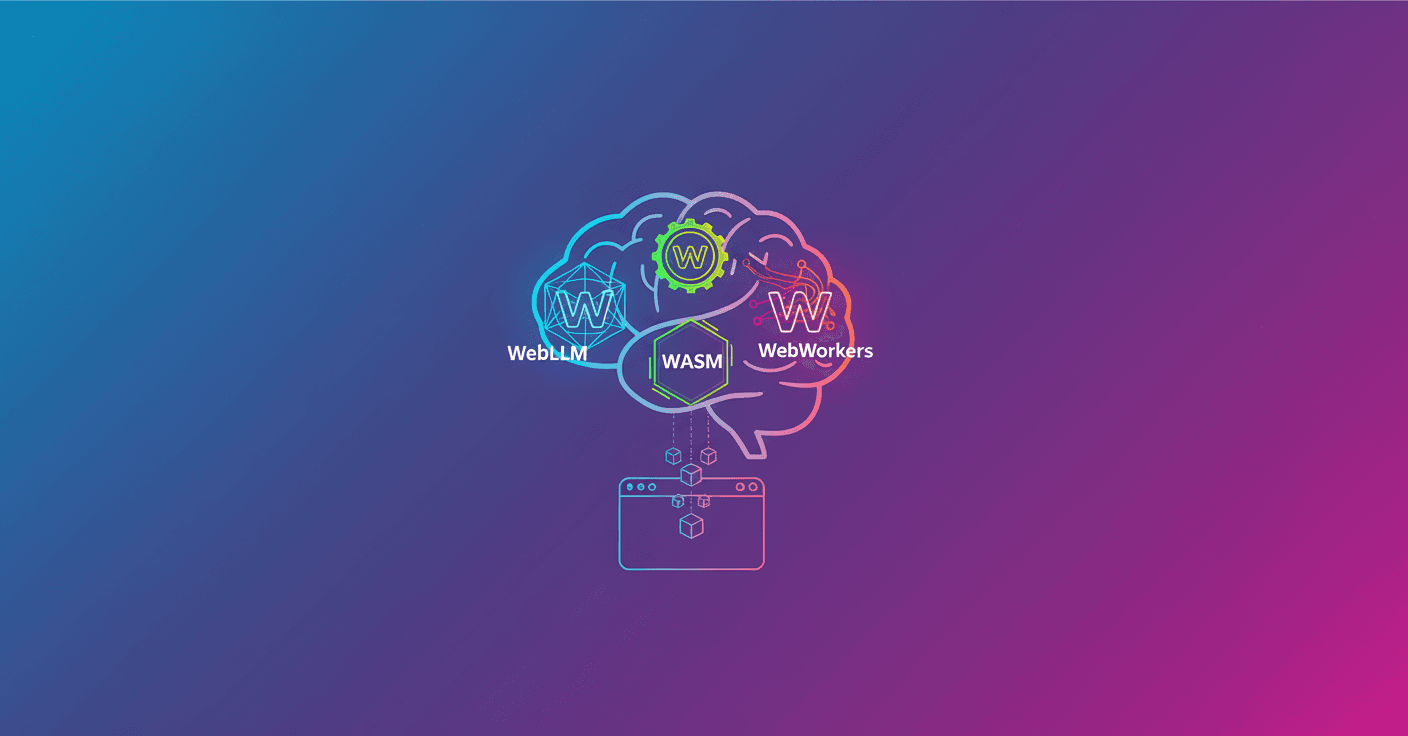
3W resume tres piezas que, juntas, buscan resolver las limitaciones clásicas de la IA en la web:
WebLLM: carga modelos cuantizados en el navegador para inferencia local.
WASM: ejecuta la lógica del agente con rendimiento cercano al nativo.
WebWorkers: mueve la ejecución fuera del hilo principal para mantener la UI responsiva.
El objetivo es desplazar la computación al cliente: menos dependencias de servidores, mayor control sobre privacidad y la posibilidad de funcionar offline. La propuesta parte de experimentos y del blueprint de WASM agents de Mozilla.ai, y lo lleva un paso más allá al poner los modelos dentro del navegador. (blog.mozilla.ai)
Cómo funciona en la práctica
La arquitectura practica un modelo multi-runtime paralelo. Cada lenguaje (Rust, Go, Python vía Pyodide y JavaScript) corre en su propio WebWorker, con su runtime WASM y una instancia de WebLLM. Eso permite escoger modelos y runtimes según la tarea, y evita el cuello de botella del JavaScript single-thread. En la demo, el flujo es simple: seleccionas un runtime y un modelo, el worker se inicializa, y las inferencias ocurren localmente sin llamadas externas. (blog.mozilla.ai)
Punto clave: todo sucede en tu navegador. No hay API keys ni tráfico hacia servidores de terceros durante la inferencia.
¿Quieres probarlo? El autor recomienda usar contenedores Docker para evitar problemas con toolchains WASM. En la entrada encontrarás instrucciones para lanzar la demo localmente y comparar runtimes y modelos. (blog.mozilla.ai)
Ventajas concretas
Privacidad por diseño: los datos nunca abandonan tu equipo.
Offline y resiliencia: útil en entornos con conectividad limitada.
Flexibilidad: cada lenguaje aporta sus fortalezas para distintos tipos de agentes.
Reducción de costos operativos para quien despliega la aplicación: cada usuario aporta su propio cómputo.
Estos beneficios abren caminos para herramientas como asistentes de código que analizan proyectos localmente, documentación interactiva en el cliente y aplicaciones educativas que no dependen de la nube. (blog.mozilla.ai)
Límites y trade offs que debes conocer
No todo es magia. El enfoque tiene puntos débiles reales:
Carga inicial: modelos grandes pueden tardar minutos en descargarse e inicializarse, lo que frustra la experiencia de usuario.
Memoria: ejecutar instancias múltiples de WebLLM puede consumir mucha RAM y hasta provocar cierres de pestañas en navegadores como Chrome.
Hardware: funciona bien en equipos recientes (menciona tests en Mac M2 Pro), pero es casi inviable en dispositivos antiguos o móviles para modelos grandes.
En resumen: es una solución potente para casos concretos y entornos controlados, pero aún no es la opción ideal para todas las aplicaciones. (blog.mozilla.ai)
Mejores usos hoy
Este enfoque tiene sentido cuando la privacidad, el control local o la capacidad offline pesan más que un arranque rápido o compatibilidad universal. Algunos ejemplos prácticos:
Entornos de desarrollo con IA que analizan el código sin subirlo a la nube.
Herramientas de documentación que responden sobre un repositorio local.
Aplicaciones para sectores regulados donde la retención de datos es crítica.
Laboratorios educativos y demos donde no quieres depender de claves o APIs externas.
¿Qué sigue y cómo puedes participar?
Los autores proponen mejoras razonables: compartir modelos entre pestañas, mejores estrategias de caching, descarga en segundo plano y cargas progresivas para reducir los tiempos iniciales. Es software experimental y el código está disponible para quien quiera jugar, modificar o contribuir. (blog.mozilla.ai)
Si te interesa indagar más, revisa la entrada original en el blog de Mozilla.ai para detalles técnicos, ejemplos y la guía para lanzar la demo localmente. ¿Qué proyecto se te ocurre que se beneficiaría de ejecutar IA totalmente en el navegador? Piensa en privacidad, offline y control: ahí está la oportunidad.
¡Mantente al día!
Recibe noticias de IA, lanzamientos de herramientas y productos innovadores directo en tu correo. Todo claro y útil.
Mozilla presenta 3W para ejecutar IA en el navegador