GPT-5.3 Codex-Spark: IA para programar en tiempo real | Keryc
OpenAI presenta GPT-5.3-Codex-Spark, una versión más pequeña y ultra rápida de Codex pensada para codificar en tiempo real. ¿Te imaginas ver cambios en tu código casi al instante mientras editas en VS Code o en la terminal? Eso es exactamente lo que quiere lograr Codex-Spark: una experiencia interactiva donde la latencia importa tanto como la inteligencia.
Qué es Codex-Spark
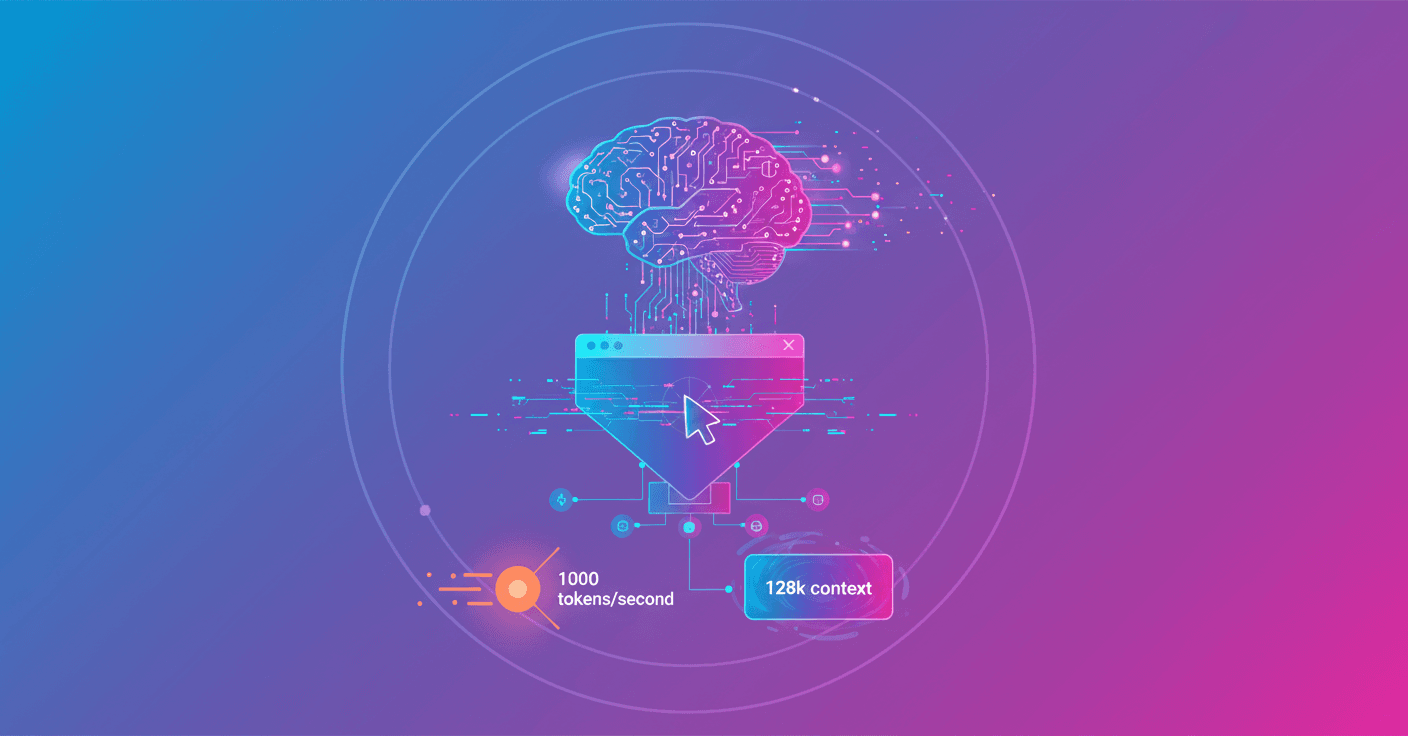
Codex-Spark es un modelo optimizado para inferencia rápida y trabajo interactivo. Es una variante más pequeña de GPT-5.3-Codex diseñada para respuestas casi instantáneas, capaz de generar más de 1000 tokens por segundo y con una ventana de contexto de 128k tokens. Por ahora es texto solamente, enfocado en edición dirigida, refinamiento de lógica y cambios rápidos en interfaces.
¿Para quién es útil? Para desarrolladores que iteran en el momento: pruebas rápidas, refactorización guiada y colaboración en tiempo real con un asistente que responde sin pausas largas.
Por qué importa ahora
La IA ya no es solo para tareas largas que se ejecutan en segundo plano. ¿Y si pudieras interrumpir, redirigir y volver a iterar con el modelo en la misma sesión, sin esperar? Codex-Spark abre esa vía, combinando dos modos: trabajo de alto nivel a largo plazo y colaboración instantánea para cuando necesitas resultados ahora.
OpenAI lo lanza como research preview para usuarios ChatGPT Pro y para un grupo pequeño de socios por API, mientras ajustan capacidad en datacenters y afinan la experiencia de usuario.
Cómo lograron esa velocidad
Hay dos piezas clave: hardware y optimizaciones en todo el pipeline.
Hardware: Codex-Spark corre en la Wafer Scale Engine 3 de Cerebras, un acelerador pensado para inferencia de baja latencia. OpenAI lo integra en su stack de producción para dar una ruta de servicio de latencia primero.
Software y pipeline: introdujeron una conexión WebSocket persistente por defecto y reescribieron partes del stack de inferencia. Eso redujo la sobrecarga por ida y vuelta cliente/servidor en 80%, la sobrecarga por token en 30% y el tiempo hasta el primer token en 50%.
Además, gracias a estas mejoras, el modelo se siente más ágil cuando iteras: no ejecuta pruebas automáticamente y hace ediciones mínimas y precisas salvo que le pidas lo contrario.
Rendimiento y comparaciones
En benchmarks orientados a ingeniería de software, como SWE-Bench Pro y Terminal-Bench 2.0, GPT-5.3-Codex-Spark mostró un buen desempeño en capacidad agentica mientras completa tareas mucho más rápido que GPT-5.3-Codex. En la práctica, eso significa entregar correctivos y cambios útiles en una fracción del tiempo.
Límites, acceso y seguridad
Acceso: rollout inicial para ChatGPT Pro en las apps Codex, CLI y la extensión de VS Code. También hay accesos API limitados para partners de diseño.
Límites de uso: durante la vista previa investigativa tiene límites de tasa separados; el uso no cuenta contra los límites estándar y puede haber cola o acceso limitado si la demanda sube.
Seguridad: Codex-Spark recibió el mismo entrenamiento de seguridad que los modelos principales, incluyendo entrenamiento orientado a riesgos cibernéticos. OpenAI evaluó que no alcanza umbrales de alta capacidad en ciberseguridad o biología según su marco de preparación.
Qué puedes esperar y qué viene después
Codex-Spark es el primer miembro de una familia de modelos ultra rápidos. A medida que la comunidad de desarrolladores lo use, veremos ajustes y nuevas capacidades: modelos más grandes, contextos aún más largos y entrada multimodal. También hay una visión clara: combinar GPUs y Cerebras en flujos de trabajo para equilibrar costo, escala y latencia.
Si trabajas en productos que necesitan interacción inmediata -editores, herramientas devops, asistentes en IDE- esto cambia el ritmo del feedback. Imagina pedir una refactorización y ver el código ajustado mientras sigues escribiendo; o iterar una interfaz y recibir pequeñas correcciones al instante.
Al final, la pregunta no es solo si la IA es capaz, sino cuán rápida y natural se siente cuando la usas. Codex-Spark adelanta ese futuro: no sustituye los modelos de larga duración, los complementa, y sobre todo reduce la fricción entre la idea y el código funcionando.