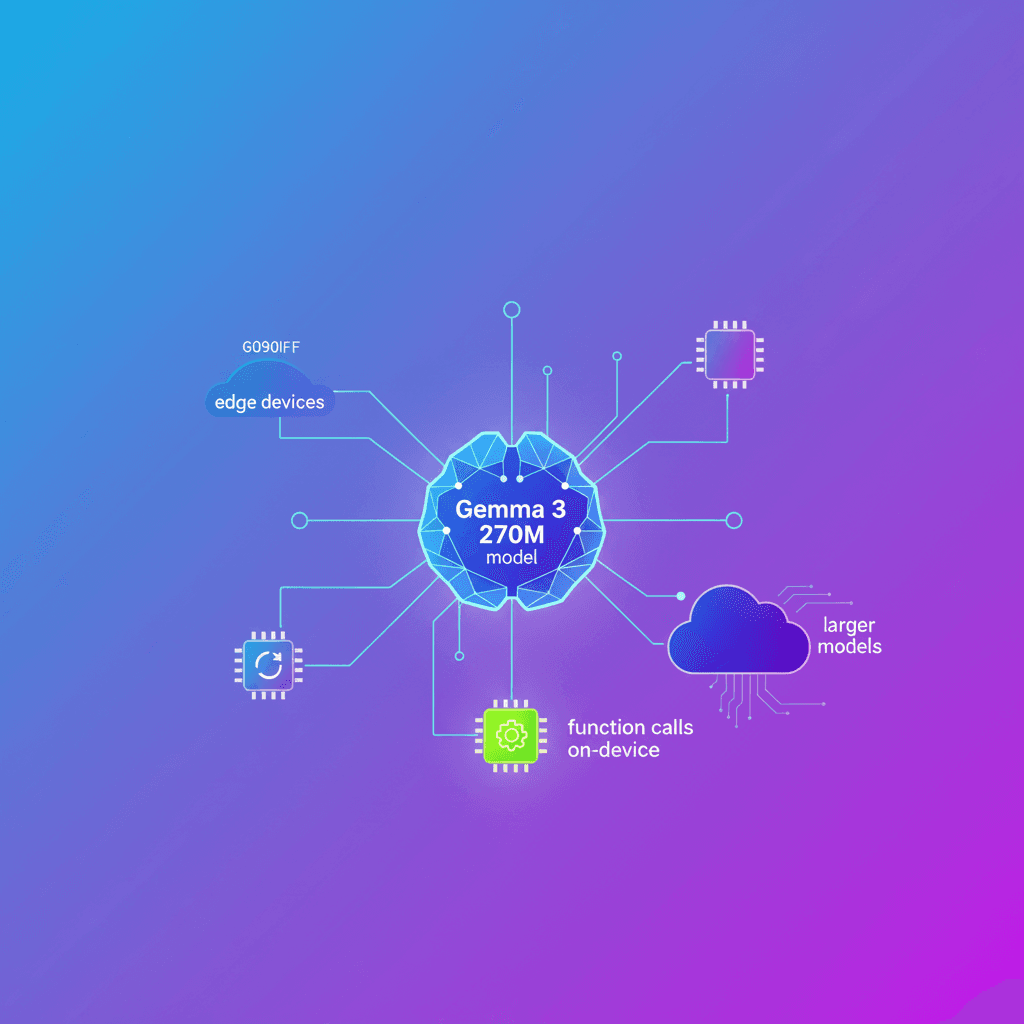
FunctionGemma llega como una apuesta concreta: no solo conversar, sino ejecutar. Google presenta una versión especializada de Gemma 3 270M optimizada para traducir lenguaje natural en llamadas a funciones ejecutables directamente en el dispositivo. ¿El objetivo? Agentes locales, rápidos y privados que pueden actuar sin depender de la nube.
Qué es FunctionGemma y por qué importa
FunctionGemma es una variante de Gemma 3 270M afinada para function calling. Está pensada como base para entrenar agentes locales que convierten instrucciones en llamadas API estructuradas, o que actúan de forma independiente para tareas offline. Además, puede trabajar como controlador de tráfico: resolver acciones comunes en el edge y delegar tareas complejas a modelos grandes como Gemma 3 27B.
¿Por qué esto cambia el juego? Porque muchos flujos ya no son solo conversaciones. Los asistentes modernos deben automatizar secuencias, tocar APIs del sistema operativo, y hacerlo con latencia mínima y total privacidad. Eso solo se consigue con modelos lo bastante pequeños para correr en el dispositivo y lo bastante especializados para ser confiables.
Características clave
-
Unified action and chat: FunctionGemma genera llamadas estructuradas a herramientas y luego vuelve a comunicar resultados en lenguaje natural. Es capaz de alternar entre protocolos machine-to-machine y human-facing sin pérdida de contexto.
-
Diseñado para personalizar: No es solo un
prompt; se construyó para ser fine-tuned. En la evaluación Mobile Actions, el ajuste fino elevó la exactitud de 58% a 85%. Eso demuestra que para agentes en el edge, un modelo dedicado y entrenado es la ruta eficiente hacia comportamiento determinista. -
Optimizado para el edge: Caben en dispositivos como NVIDIA Jetson Nano y teléfonos móviles. Usa la tokenización de Gemma con
256k vocabulary, lo que hace más eficiente el tokenizado de JSON y entradas multilingües. Reducir la longitud de secuencia permite latencias más bajas y menor uso de memoria. -
Ecosistema amplio: Soporta frameworks para entrenamiento y despliegue como Hugging Face Transformers, Unsloth, Keras y NVIDIA NeMo. Para inferencia y deployment puedes usar LiteRT-LM, vLLM, MLX, Llama.cpp, Ollama, Vertex AI o LM Studio.
Nota importante: pensar en local-first no es solo rendimiento. Es también privacidad. Si tu flujo maneja datos sensibles, ejecutar la lógica en el dispositivo evita enviar contexto a servidores externos.
Casos de uso y cuándo elegirlo
¿Te sirve FunctionGemma? Probablemente sí si:
- Tienes una superficie de API definida: controles de hogar inteligente, media player, navegación o herramientas del sistema.
- Estás dispuesto a fine-tune: quieres comportamiento consistente, repetible, con menos variabilidad que el zero-shot.
- Priorizar local-first: necesitas latencia cercana a cero y privacidad total.
- Construyes sistemas compuestos: un modelo ligero en el edge atiende lo frecuente y rápida, y uno grande en la nube resuelve los casos raros o complejos.
Ejemplos concretos: crear eventos en calendario sin conexión, agregar contactos, encender la linterna, o manejar mecánicas de juego en TinyGarden donde una instrucción como "plantar girasoles en la fila superior y regarlos" se descompone en plantCrop y waterCrop con coordenadas específicas.
Demos y experiencia práctica
Google muestra tres demos útiles para entender el flujo:
- Mobile Actions fine tuning: una demostración de un asistente 100% offline que ejecuta comandos del sistema operativo en el dispositivo.
- TinyGarden: juego donde el modelo controla mecánicas por voz en el teléfono sin enviar datos a la nube.
- FunctionGemma Physics Playground: puzzles de física que corren localmente en el navegador con Transformers.js.
Estas demos no son ornamentales. Son pruebas de que un modelo de 270M puede manejar lógica multi-turn y acciones concretas en tiempo real.
Cómo probar FunctionGemma hoy
- Descargar: el modelo está disponible en Hugging Face y Kaggle.
- Aprender: hay guías sobre plantillas de function calling, cómo secuenciar respuestas y cómo fine-tunear.
- Explorar: la Google AI Edge Gallery incluye los demos interactivos.
- Construir: hay un Colab y un dataset para entrenar tu propio agente Mobile Actions.
- Desplegar: publica modelos en móviles con LiteRT-LM o combínalo con modelos más grandes en Vertex AI o hardware NVIDIA como RTX PRO y DGX Spark.
Consideraciones técnicas para desarrolladores
-
Fine-tuning vs prompt engineering: para tareas deterministas en el edge, el fine-tuning suele ganar. La variación del zero-shot puede ser inaceptable en sistemas que tocan APIs del usuario.
-
Tokenización y eficiencia: la
256k vocabularyayuda a tokenizar eficientemente JSON y reducir la longitud de secuencia. Menos tokens implican menor latencia y menor uso de memoria en dispositivos limitados. -
Orquestación híbrida: diseña una jerarquía donde FunctionGemma resuelve lo local y frecuente. Define criterios claros para elevar requests a un modelo grande. Esto reduce costos y mantiene tiempos de respuesta.
-
Herramientas y runtime: pruebalos y mide latencia de inferencia y consumo de energía en tu target.
vLLMyLiteRT-LMson opciones para producción;Llama.cppyOllamasirven bien para prototipos y pruebas locales.
Reflexión final
FunctionGemma confirma una dirección clara: los modelos ya no son solo para conversar. Son intermediarios entre tu lenguaje y el mundo de las APIs. Si estás construyendo productos que necesitan velocidad, privacidad y acciones deterministas, este tipo de modelos te permite despliegues locales reales. ¿Listo para convertir conversaciones en acciones reales en el dispositivo?