Si alguna vez te has preguntado por qué tus GPUs pasan gran parte del tiempo ociosas cuando entrenas modelos que razonan, esta nota es para ti. Aquí tienes la versión técnica y digerible de un estudio amplio: 16 librerías open source que ya resolvieron (en distintas formas) el problema del entrenamiento asíncrono en RL para modelos de razonamiento largo.
El problema en pocas palabras
En un bucle de RL tradicional, la generación autoregresiva (inferencia) se come la mayor parte del tiempo de pared. Un solo batch de rollouts de 32K tokens en un modelo de 32B puede tardar horas, mientras las GPUs de entrenamiento están paradas.
¿La consecuencia? Baja utilización de GPU, latencias enormes y cuellos de botella por el llamado problema del straggler: unas pocas muestras lentas bloquean lotes enteros.
Ejemplo numérico rápido (benchmarks vLLM, H100 80GB, bf16):
7B≈ 6,300 tokens/s agregado.32B≈ 1,200 tokens/s agregado.
Eso significa, por ejemplo, que 512 rollouts de 8K tokens sobre un 32B pueden tardar casi una hora en una sola GPU. ¿Te imaginas esperar eso cada paso de entrenamiento?
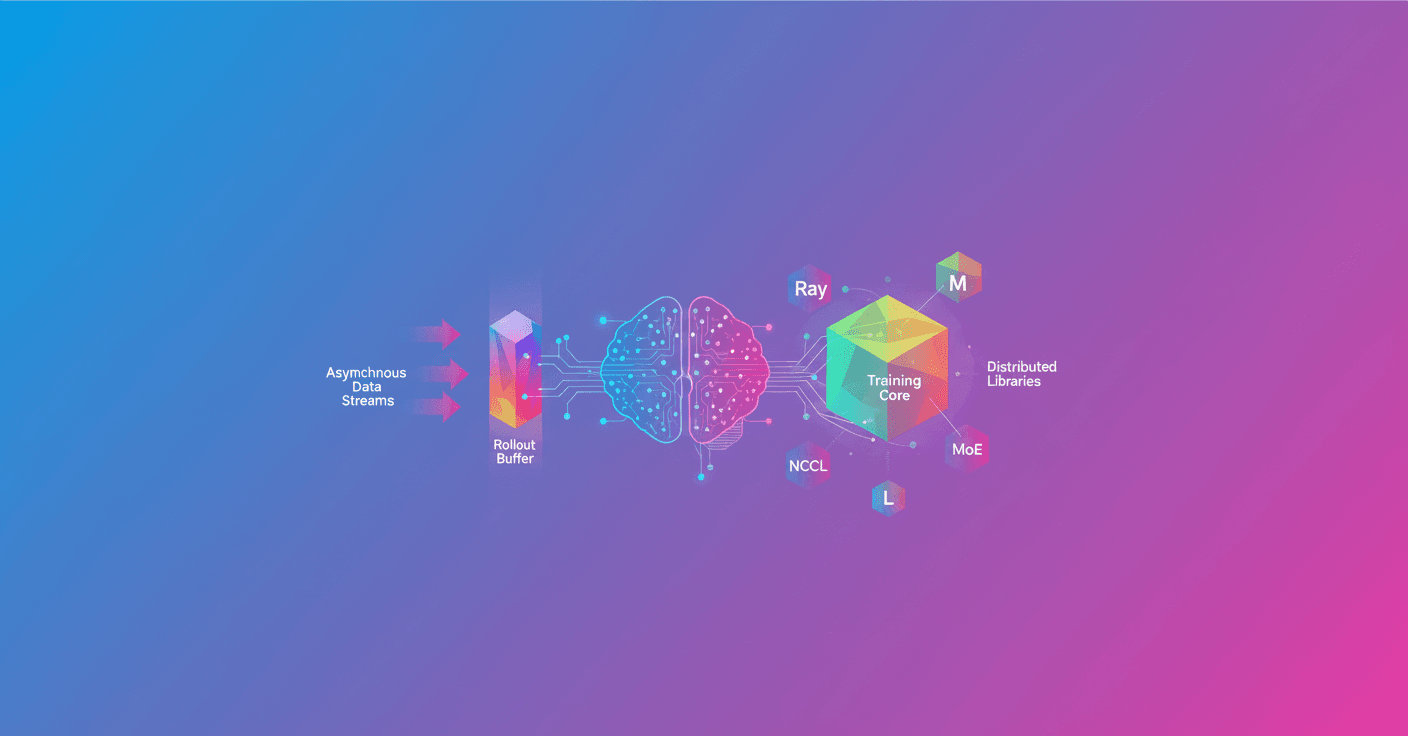
La solución que se impone: disociar y poner flujo
El patrón dominante es simple y potente:
- Disagregar la inferencia y el entrenamiento en pools GPU separados.
- Conectar ambos con un rollout buffer que actúe como amortiguador.
- Sincronizar pesos de forma asíncrona para que ninguna parte espere a la otra.
Así la inferencia genera N+K rollouts mientras el optimizador actualiza con los rollouts N, aprovechando hardware en paralelo.
Las siete dimensiones que determinan el diseño
Para comparar arquitecturas, el estudio propone siete ejes clave. Te los dejo como una checklist para cuando evalúes o diseñes tu propia infraestructura:
- Orquestación y primitiva de concurrencia: Ray, asyncio, pub/sub, HTTP, Monarch, etc.
- Diseño del buffer: sin buffer, doble buffer, cola acotada, stream ilimitado.
- Protocolo de sincronización de pesos: NCCL broadcast, filesystem, HTTP, CUDA IPC, bucketing.
- Gestión de staleness: rechazo por versión, acotado por profundidad, corrección por importancia sampling (IS).
- Manejo de rollouts parciales: continuar, abortar y reintentar, guardar/resumir, drenar antes de sync.
- Soporte LoRA: sync solo de adaptadores vs full-parameter sync.
- Backend de entrenamiento y paralelismo: FSDP, DeepSpeed, Megatron, JAX/XLA, soporte MoE y EP.
Cada una de estas decisiones cambia rendimiento, complejidad y correcciones numéricas necesarias.
Hallazgos clave del relevamiento (resumido)
- Ray domina la orquestación: 8 de 16 librerías. El actor model encaja naturalmente en componentes heterogéneos.
- NCCL broadcast es la ruta por defecto para transferir pesos; varias implementaciones usan bucketed NCCL para reducir latencia.
- Staleness se maneja con tres estrategias: drop por versión, depth bounding (cola acotada) o IS-weighted loss. Las soluciones reales suelen combinar enfoques.
- LoRA está soportado en muchas librerías, pero el adapter-only sync aún no es universal. Cuando existe, transforma el problema de sync (del orden de GB pasa a MB).
- MoE y EP se vuelven el diferenciador emergente; no todas las librerías soportan Expert Parallelism correctamente. Esto complica routing, sync y LoRA por experto.
- Interrupción de generación tiene múltiples granularidades: desde never-stop por forward-pass (p. ej.
PipelineRL) hasta bloqueo por batch o paso.
Modelos de interrupción y transferencia de pesos
El comportamiento al actualizar pesos define cuánto se desperdicia trabajo en curso:
- Never-stop (swap entre forward passes) permite interrupciones de milisegundos.
- Per-request abort + resume recicla trabajo parcial pero añade complejidad.
- Soft pause (drenar in-flight) evita abortos pero introduce burbujas de sincronización.
- Full-step/blocking es simple pero caro en tiempo ocioso.
En el transporte, el bucketing NCCL puede bajar latencias de cientos de ms a decenas de ms en implementaciones optimizadas.
Datos concretos para dimensionar (tabla resumida)
| Output por rollout | Tokens totales (512) | 7B (6.3K tok/s) | 32B (1.2K tok/s) |
|---|---|---|---|
| 2K | ~1M | ~3 min | ~14 min |
| 8K | ~4M | ~11 min | ~56 min |
| 32K | ~16M | ~45 min | ~3.7 hours |
Estos números explican por qué la comunidad migró a arquitecturas asíncronas.
Casos complejos y problemas emergentes
No todo se arregla con una cola y NCCL. Algunos retos que aparecen en producción:
- Critic-free algorithms reducen memoria, pero aumentan presión de sync porque requieren más rollouts por paso.
- Process reward models (PRM) hacen el scoring costoso y requieren pipelines de scoring asíncronos.
- Multi-agent y co-evolución multiplican el efecto straggler; la unidad de trabajo pasa a ser episodios, no rollouts sueltos.
- Training-inference mismatch en MoE: el routing de expertos puede diferir entre inferencia y entrenamiento. Necesario: 'Keep Routing' (registro y reuso del routing durante el forward de entrenamiento).
- Sampling mask mismatch: top-k/top-p cambia el espacio de acciones entre sampling y evaluación; hay que registrar y reaplicar la mask para que IS sea válido.
Si trabajas con MoE, estos son problemas de corrección, no solo de rendimiento.
Relevancia de LoRA y LoRA para MoE
LoRA reduce el tamaño de la transferencia a un par de MB cuando el servidor de inferencia soporta hot-swap de adaptadores. Eso hace viable la mayoría de modelos de producción con sync prácticamente indetectable. Pero en MoE:
- Cada experto puede necesitar sus adaptadores. Con 64 expertos, el número de adaptadores escala y los adapters están distribuidos por EP ranks.
- Sync de LoRA en MoE implica gather de adaptadores desde múltiples ranks antes de empujar al inference server.
En la práctica, pocas librerías (p. ej. ART con Megatron EP) implementan MoE-LoRA de forma completa.
Diseño propuesto para el async trainer de TRL (concreto y técnico)
Si fueras a diseñarlo desde cero, estas son las decisiones sugeridas por el estudio:
- Mantener la simplicidad del stack: evitar runtime pesado como dependencia obligatoria, pero diseñar la API para integrarlo si el usuario lo necesita.
- Ir directo a una cola acotada donde cada token tenga un
model_versiontag. Eso permite corrección por IS a granularidad de token y gating por estaleness sin deuda técnica. - Usar NCCL process groups con bucketing para empaquetar parámetros y reducir llamadas. vLLM y engines similares ya soportan packed broadcasts.
- Explorar engines de sync avanzados (Awex, Mooncake) para convertir entre layouts de entrenamiento (Megatron, FSDP) y layouts de inferencia (vLLM, SGLang) sin full checkpoint.
- Soporte LoRA desde el día 1, con path optimizado para adapter-only sync cuando el inference server lo acepte.
- Probar dos estrategias para rollouts en curso al llegar una actualización: prefix-resume (guardar KV cache y retomar) y abort-and-retry. Cada una tiene trade-offs; el prefijo retiene compute pero necesita soporte en el engine de inferencia.
- Registrar metadata extra durante la generación: routing de expertos, sampling masks, logprobs token-level. Sin eso no puedes garantizar corrección IS ni reproducibilidad en MoE.
Recomendaciones prácticas para equipos
- Si tu escala es < 16 GPUs y controlas todo el stack, una solución basada en
asyncio+ Redis streams puede bastar. - Para producción 64+ GPUs, Ray (o Monarch) facilita scheduling, autoscaling y tolerancia a fallos.
- Implementa LoRA adapter-only sync si tu inference engine lo soporta; cambia el problema de sync para siempre.
- Para MoE, exige EP-aware training y un plan de weight sync que tenga en cuenta AllGather por experto.
- Añade telemetría de versiones por token desde el inicio; corregir staleness sin ese dato es costoso.
Reflexión final
La lección práctica es clara: la arquitectura asíncrona dejó de ser experimental. Separar inferencia y entrenamiento, definir un buffer bien pensado y diseñar protocolos de sync y staleness son requisitos para entrenar modelos que razonan a escala. ¿Te da miedo la complejidad? Perfecto, es una buena señal: la complejidad te pide que diseñes métricas de salud, gates de staleness y pruebas automatizadas. Si lo resuelves bien, tus GPUs dejarán de dormir y tu investigación podrá avanzar mucho más rápido.