We're in a clear transition: models that do single tasks well are no longer enough; now we're looking for agents that can run complete workflows. What changes for you? Instead of just asking a model to reason, you give it a computer environment so it can run commands, read files, call APIs, and produce useful artifacts like spreadsheets or reports.
What problem does this solve
Have you ever ended up pasting giant tables into a prompt or rewriting file-handling logic every time? That happens because models, by themselves, only propose actions; they don't execute them. The practical problems are obvious: where do you store intermediate files? how do you avoid overloading the prompt? how do you give network access without opening a security hole? and what about timeouts and retries?
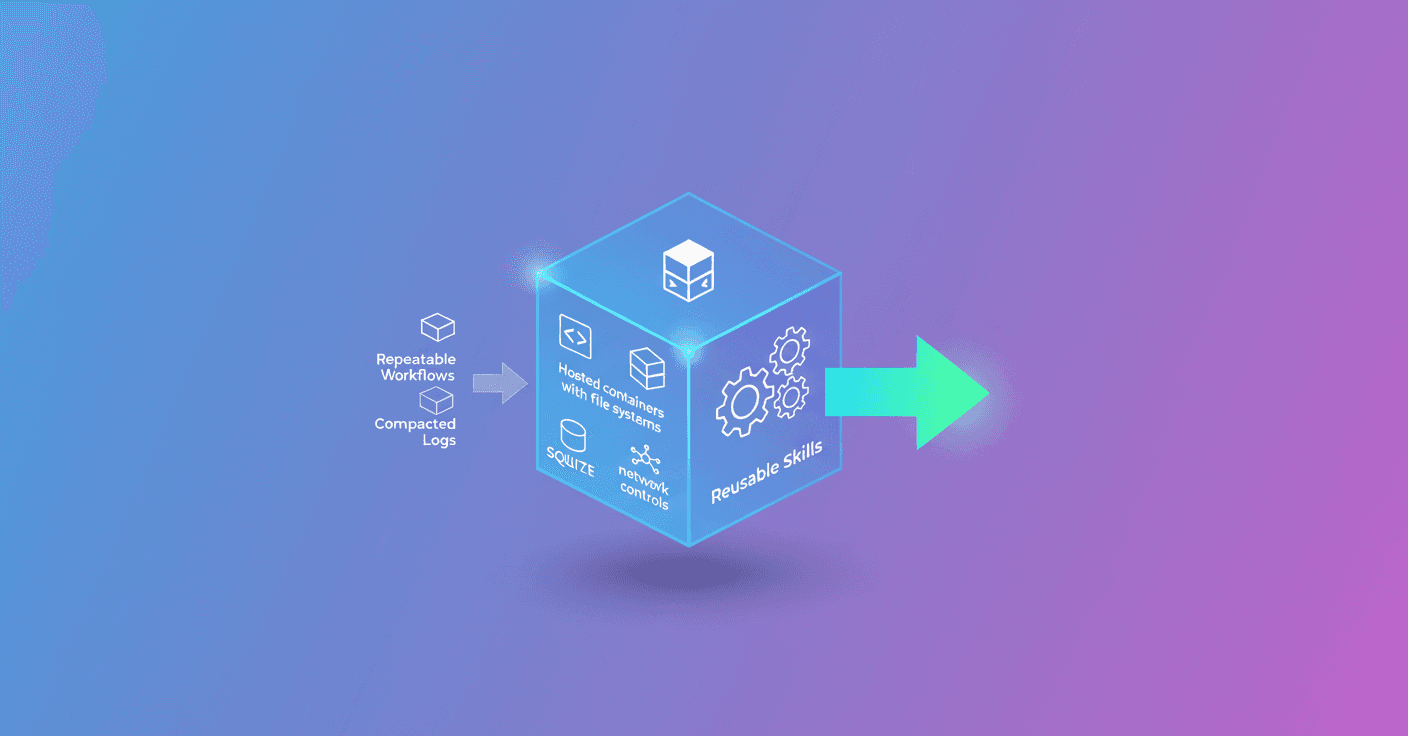
OpenAI doesn't leave all that to the developer. They equipped the Responses API with a computer environment made of: a shell tool, a hosted container with a file system, optional structured storage (for example SQLite), and network controls. The idea: the model proposes steps and commands; the platform executes them in isolation and returns results to the model in a loop.
How the execution loop works
The basic pattern is a closed execution loop: the model decides an action (read a file, make a request), the platform executes it, and the result returns to the model for the next step. The simplest piece to see in action is the shell tool.
The shell tool lets the model propose commands like grep, curl, awk, or start servers in NodeJS, Go, or Java. But remember: the model proposes commands; the platform is the one that runs them.
The Responses API acts as orchestrator: when the model suggests a command, the API sends it to the container, streams the output back to the model, and repeats until the model emits a final response with no more commands. This lets you inspect results almost in real time and issue follow-up commands.
You can also parallelize work: the model can propose several commands and the API runs them in separate container sessions. Each session streams its output and the API merges those streams in a structured way so the model can reason about them.
Output control and context efficiency
Console logs can be enormous and eat up your context budget. To avoid that, the model can request a limit per command. The Responses API returns a bounded result that preserves the beginning and the end of the output, for example:
text at the beginning ... 1000 chars truncated ... text at the end
With concurrent execution and truncated results, the agent stays fast and focused: it doesn't get lost in mountains of logs.
Keeping coherence in long sessions: compaction
Long flows fill the context window. How do you keep what's important without loading everything? The solution is native compaction: models analyze prior state and generate a compacted item that encodes the essentials efficiently and encrypted.
The Responses API can compact automatically on the server or via the /compact endpoint. This saves you from building manual summaries and lets multi-stage flows stay coherent even if they exceed the input window.
Files, databases and network access
The container is the workspace: it has a file system to upload and organize resources. Instead of stuffing everything into the prompt, you upload data to the container and the model decides what to open with ls, cat, or other commands. That way you work with organized, efficient information.
For structured data, they recommend using databases like SQLite: describe the tables to the model and let it make precise queries instead of pasting an entire sheet. It's faster, cheaper, and scales better.
Network access is managed through an outbound proxy (a sidecar). All requests go through a centralized policy layer with allowlists and controls. Credentials are injected with domain-scoped placeholders: the model and the container see placeholders while the real secrets remain out of visible context until the call is approved. That reduces the risk of leaks and enables secure authenticated calls.
Skills: repeat without replanning every time
Many flows repeat the same steps. Agents would otherwise have to rediscover them each run. That's why there are skills: packaged folders with a SKILL.md (metadata and instructions) and supporting resources (API specs, scripts, assets).
The runtime follows a deterministic sequence when loading a skill:
- Retrieve metadata (name, description).
- Download and unpack the bundle into the container.
- Update the model's context with the path and metadata.
The model can explore the skill with ls and cat and run scripts inside the same agent loop. The platform also offers APIs to version and manage skills.
A quick example in one sentence
With these pieces, a single prompt can: discover the right skill, fetch live data, transform it into local structured state, query only what's necessary, and generate a durable file like a spreadsheet.
So what's next? For developers, this opens the door to agents that not only suggest steps but execute them in a repeatable and secure way. For teams, it means less homemade infrastructure to orchestrate, summarize, and secure workflows.
The bet is clear: move from a world where models return text to one where agents, backed by a controlled computational environment, solve real-world tasks.
Original source
https://openai.com/index/equip-responses-api-computer-environment