Mozilla introduces 3W to run AI in the browser | Keryc
Can you imagine running a full language model inside your browser, with no external API calls and without your data leaving your machine? Mozilla.ai published a guest post proposing exactly that: an approach called 3W that combines WebLLM, WASM and WebWorkers to run inference and agent logic directly in the browser. (blog.mozilla.ai)
What 3W is and why it matters
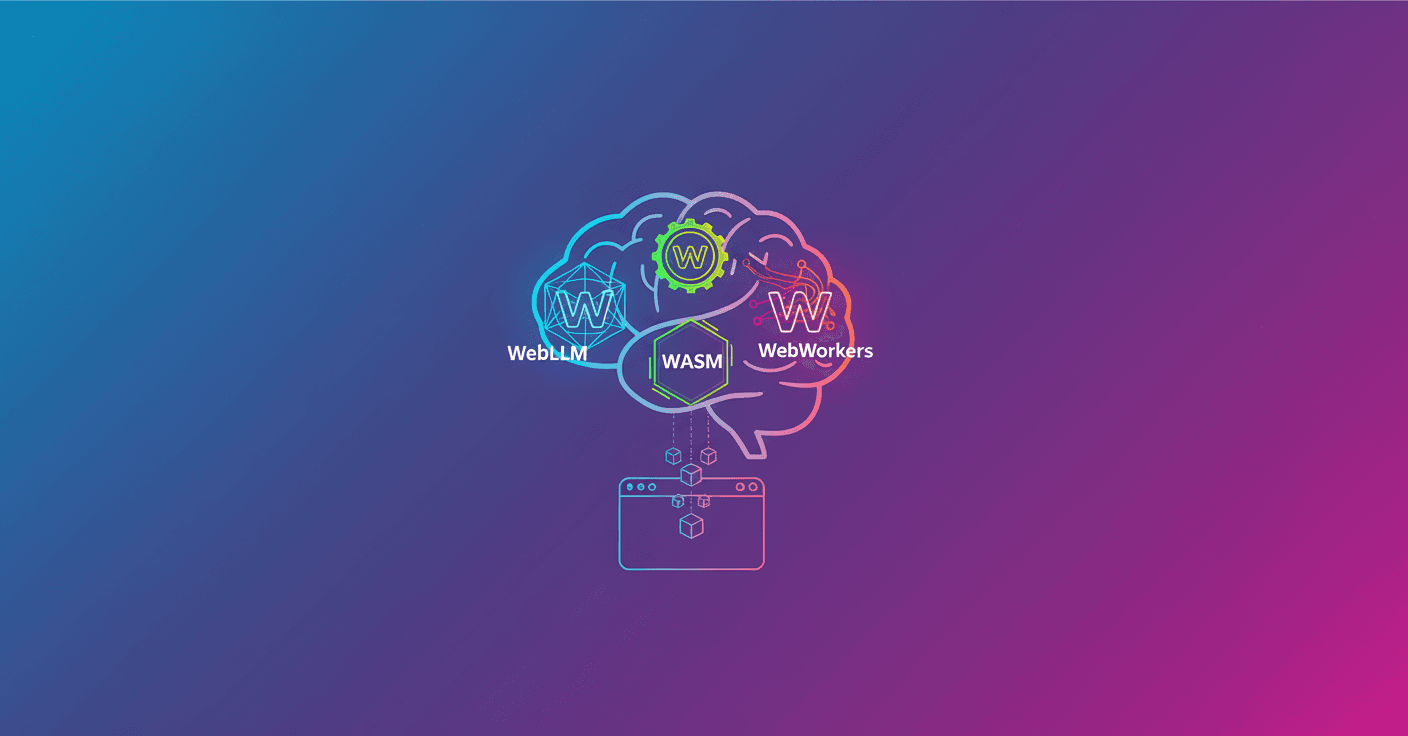
3W sums up three pieces that, together, aim to solve the classic limitations of web AI:
WebLLM: loads quantized models in the browser for local inference.
WASM: runs the agent logic with near-native performance.
WebWorkers: moves execution off the main thread to keep the UI responsive.
The goal is to shift computation to the client: fewer server dependencies, more control over privacy, and the ability to work offline. The proposal builds on experiments and Mozilla.ai’s WASM agents blueprint, and takes it further by placing the models inside the browser. ()
The architecture uses a parallel multi-runtime model. Each language (Rust, Go, Python via Pyodide and JavaScript) runs in its own WebWorker, with its WASM runtime and an instance of WebLLM. That lets you pick models and runtimes by task, and avoids the single-thread JavaScript bottleneck.
In the demo, the flow is simple: you choose a runtime and a model, the worker initializes, and inferences happen locally without external calls. (blog.mozilla.ai)
Key point: everything happens in your browser. There are no API keys or traffic to third‑party servers during inference.
Want to try it? The author recommends using Docker containers to avoid issues with WASM toolchains. The post includes instructions to launch the demo locally and compare runtimes and models. (blog.mozilla.ai)
Concrete advantages
Privacy by design: your data never leaves your machine.
Offline and resilience: useful where connectivity is limited.
Flexibility: each language brings strengths for different kinds of agents.
Lower operational costs for deployers: each user provides their own compute.
These benefits open possibilities for things like code assistants that analyze projects locally, interactive client-side documentation, and educational apps that don’t rely on the cloud. (blog.mozilla.ai)
Limits and trade-offs you should know
It’s not magic. The approach has real weak points:
Initial load: large models can take minutes to download and initialize, which frustrates user experience.
Memory: running multiple WebLLM instances can consume lots of RAM and even crash tabs in browsers like Chrome.
Hardware: it works well on recent machines (they mention tests on an M2 Pro), but it’s close to impossible on older devices or phones for big models.
In short: it’s a powerful solution for specific cases and controlled environments, but not yet the ideal choice for every application. (blog.mozilla.ai)
Best uses today
This approach makes sense when privacy, local control or offline capability matter more than a fast startup or universal compatibility. Some practical examples:
Dev environments with AI that analyzes code without uploading it to the cloud.
Documentation tools that answer questions about a local repo.
Apps for regulated sectors where data retention is critical.
Educational labs and demos where you don’t want to depend on keys or external APIs.
What’s next and how you can participate?
The authors suggest reasonable improvements: sharing models between tabs, better caching strategies, background downloads and progressive loading to reduce initial times. It’s experimental software and the code is available if you want to play, modify or contribute. (blog.mozilla.ai)
If you want to dig deeper, check the original post on the Mozilla.ai blog for technical details, examples and the guide to run the demo locally. What project can you imagine benefiting from running AI entirely in the browser? Think privacy, offline and control — that’s where the opportunity is.
Stay up to date!
Get AI news, tool launches, and innovative products straight to your inbox. Everything clear and useful.