In many Rails monoliths, development prioritizes new features and tests get left for later. What happens? You end up with untested code that causes bugs that are hard to reproduce and hours lost debugging.
Mistral introduced an autonomous agent that closes that gap: it reads files in a Rails project, generates or improves RSpec specs, validates style and coverage, and runs everything inside the CI/CD pipeline without human intervention. Sounds like magic? It's applied engineering: it automates repetitive steps and forces tests to actually run.
What problem it solves
Can you imagine a codebase where half the files never had tests? That was the starting point. Teams that write features but skip tests create growing technical debt. The agent acts on concrete files (models, controllers, serializers, mailers, helpers) and takes care of generating or improving the associated specs.
Ruby is dynamic: there is no compilation that catches errors. That complicates the agent: the only reliable way to verify a spec's syntax and validity is to run it. That's why Mistral runs the tests as part of the agent's workflow.
How the agent works (practical summary)
- Reads the source file and any available documentation.
- Looks for an associated spec; the convention between
app/...andspec/...makes this easier. - Picks a skill specialized by file type (for example, controllers have different rules than models).
- Reuses or creates
factorieswhen needed, carefully to avoid breaking cross-tests. - Runs linters and coverage tools:
RuboCopfor style andSimpleCovtogether with RSpec to ensure tests run and cover important lines. - Self-reviews: it counts public methods and asks "did I test all public methods?" before finishing.
What if a test fails when executed? The agent rewrites and fixes until the test passes or it reaches the quality criteria.
Vibe: the platform where the agent runs
They built this flow on Vibe, Mistral's open source coding assistant. Instead of a generic prompt, they used three levers:
- repository-level context (an
AGENTS.mdwith an execution plan), - skills specialized by file type,
- and custom tools that can execute commands and read results.
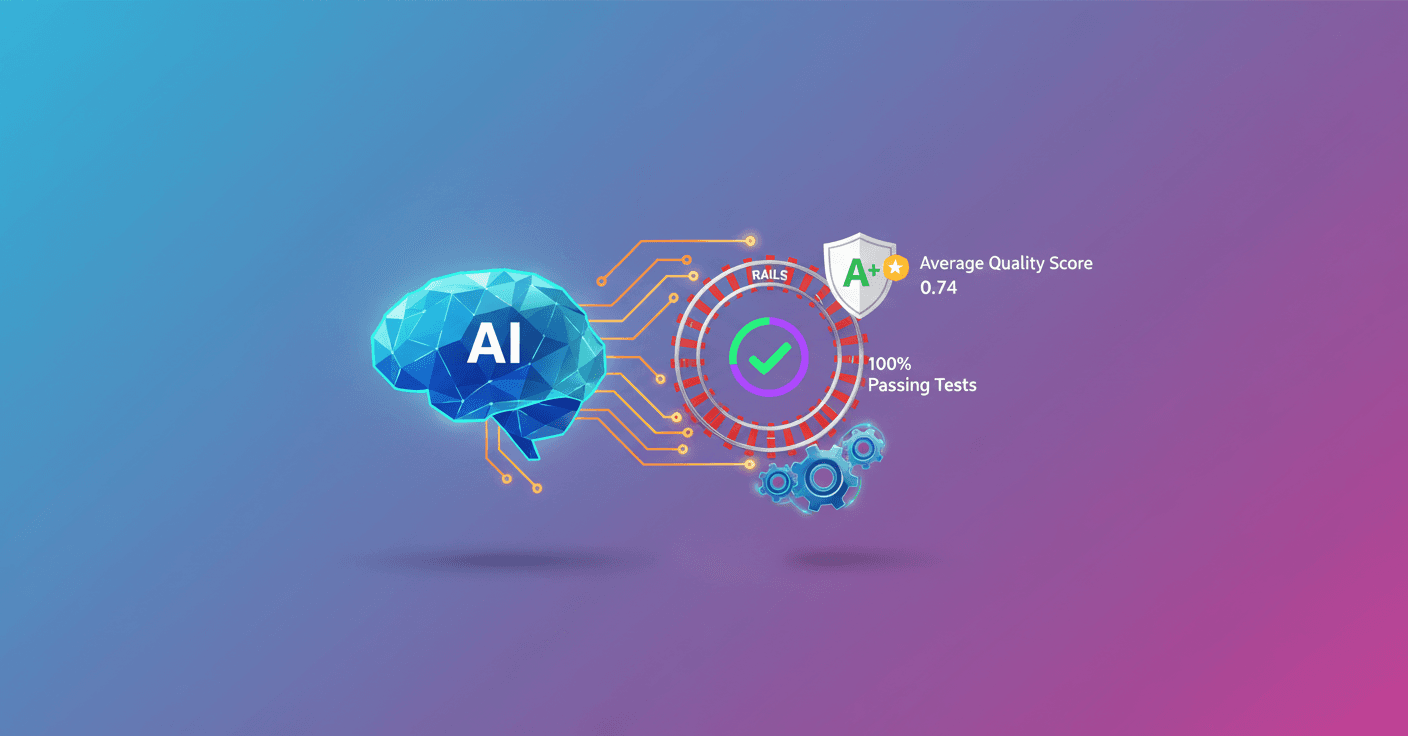
The AGENTS.md included a step-by-step list with concrete success criteria and RSpec style rules (for example, avoid vague matchers like be_truthy and prefer eq(exact_value)). That single file raised the agent's quality score from 0.68 to 0.74.
Skills and rules for each file type
A skill is a recipe for how to write tests for a file type. For example, the controller skill specifies:
- where to create the spec (
spec/requests/..._spec.rb), - rules: assert JSON content, verify state changes with
change { Model.count }.by(1), and test authorized and unauthorized routes, - cover actions: index, show, create, update, destroy and custom actions.
Separating instructions by type prevents a single mediocre prompt from guessing how to test everything.
Key tools: RuboCop and SimpleCov (and why to run them)
Two practical decisions made the difference:
- use RuboCop to detect and fix style violations, and
- use SimpleCov integrated with RSpec to force each test to run and measure coverage per file.
Without running tests, a spec can look perfect on paper but fail to run due to syntax errors, missing dependencies, or nonexistent factories. By running everything, the agent could self-correct: only 1/3 of tests passed on the first attempt; after automatic iterations they reached 100% passing tests in the experiment.
Running the tests is not a luxury: it's what separates pretty tests on paper from tests that actually protect the code.
LLM-as-a-judge: evaluating quality beyond metrics
Besides classic metrics (percentage of passing tests, RuboCop violations, SimpleCov coverage), they used an approach called LLM-as-a-judge: ask a model to score a spec between 0 and 1 based on clear rules (does it cover errors? does it use precise assertions? does it test edge cases?).
This helps capture qualitative quality, but has limits: the evaluation isn't 100% deterministic and can fail if a test has good intent but doesn't run due to a syntax error.
The missing parenthesis problem (a useful example)
RSpec.describe User, "#full_name" do it "combines first and last name" do user = User.new(first_name: "Ada", last_name: "Lovelace" expect(user.full_name).to eq("Ada Lovelace") end end
This spec is well written in intention and assertion, but it will never run because of a missing parenthesis. An LLM can score it high if it only evaluates intent, which is why actual execution with SimpleCov was key to detect and fix these failures.
Experiment results
Metrics from the experiment on a repository with 275 files:
- Files processed: 275
- Tests passing: 100%
- Average coverage per file (SimpleCov): 100%
- RuboCop violations after fixes: 0
- LLM-as-a-judge score (average): 0.74
Breakdown by file type (LLM-as-a-judge):
- Models: 0.81
- Controllers: 0.67
- Serializers: 0.80
Models were easier because their logic is self-contained; controllers require handling HTTP, authentication, and more dependencies.
Limitations and practical warnings
- It's not a magic solution: you must maintain the
factoriesand testing dependencies. - Changes in factories can break broad tests: the agent modifies factories cautiously.
- LLM evaluations are noisy; aggregating at scale mitigates variability.
- Incompatible gem versions or syntax can cause errors that require human intervention in complex cases.
Why this matters for you
If you work on a large Rails codebase, this means less repetitive manual work and less accumulated technical debt. Want tests to exist and actually serve a purpose? Make them run, measure them, and automate feedback. That's the simple principle that turned an experiment into a practical tool.